Programmers 84325 : 직업군 추천하기
문제
개발자가 사용하는 언어와 언어 선호도를 입력하면 그에 맞는 직업군을 추천해주는 알고리즘을 개발하려고 합니다.
아래 표는 5개 직업군 별로 많이 사용하는 5개 언어에 직업군 언어 점수를 부여한 표입니다.

예를 들면, SQL의 SI 직업군 언어 점수는 3점이지만 CONTENTS 직업군 언어 점수는 2점입니다. SQL의 HARDWARE, PORTAL, GAME 직업군 언어 점수는 0점입니다.
직업군 언어 점수를 정리한 문자열 배열 table, 개발자가 사용하는 언어를 담은 문자열 배열 languages, 언어 선호도를 담은 정수 배열 preference가 매개변수로 주어집니다. 개발자가 사용하는 언어의 언어 선호도 x 직업군 언어 점수의 총합이 가장 높은 직업군을 return 하도록 solution 함수를 완성해주세요. 총합이 같은 직업군이 여러 개일 경우, 이름이 사전 순으로 가장 빠른 직업군을 return 해주세요.
제한 사항
- table의 길이 = 5
- table의 원소는 “직업군 5점언어 4점언어 3점언어 2점언어 1점언어”형식의 문자열입니다. 직업군, 5점언어, 4언어, 3점언어, 2점언어, 1점언어는 하나의 공백으로 구분되어 있습니다.
- table은 모든 테스트케이스에서 동일합니다.
- 1 ≤ languages의 길이 ≤ 9
- languages의 원소는 “JAVA”, “JAVASCRIPT”, “C”, “C++” ,”C#” , “SQL”, “PYTHON”, “KOTLIN”, “PHP” 중 한 개 이상으로 이루어져 있습니다.
- languages의 원소는 중복되지 않습니다.
- preference의 길이 = languages의 길이
- 1 ≤ preference의 원소 ≤ 10
- preference의 i번째 원소는 languages의 i번째 원소의 언어 선호도입니다.
- return 할 문자열은 “SI”, “CONTENTS”, “HARDWARE”, “PORTAL”, “GAME” 중 하나입니다.
입출력 예시
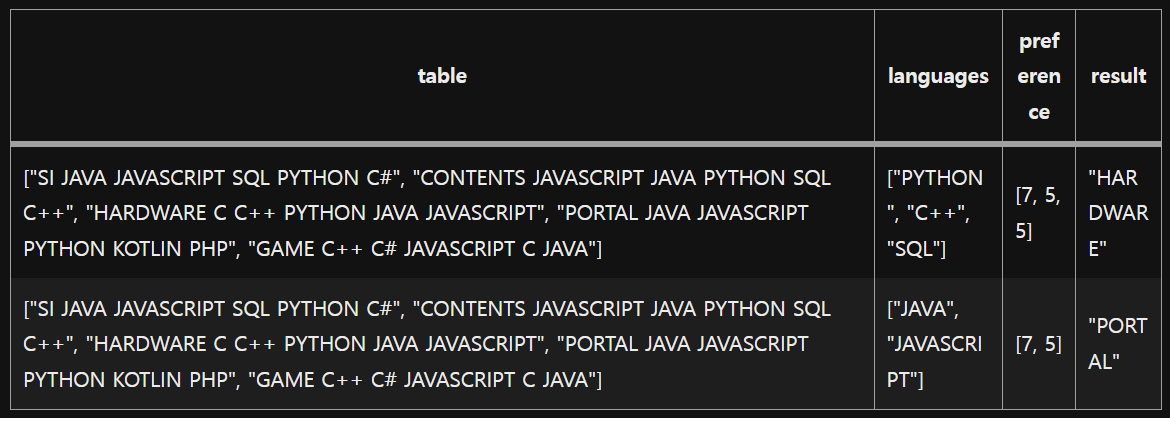
Source
# # len(table) == 5
# # table = ["직업군 5점언어 4점언어 3점언어 2점언어 1점언어"]
# # 1 <= len(languages) <= 9
# # language 종류: "JAVA", "JAVASCRIPT", "C", "C++" ,"C#" , "SQL", "PYTHON", "KOTLIN", "PHP"
# # len(preference) == len(languages)
# # return 할 문자열: "SI", "CONTENTS", "HARDWARE", "PORTAL", "GAME"
# def solution(table, languages, preferenece):
# lan_index = []
# new_table = [[0 for _ in range(5)] for _ in range(5)]
# for i in range(len(languages)):
# lan_index.append(i + 1)
# for i in table:
# for j in i.split(' '):
# new_table[i].append(j)
# for i in range(1, len(new_table)):
# point = []
# for j in new_table[i]:
# point.append(j)
# point.reverse()
# for k in languages:
# if languages[k] == new_table[i][j]:
# lan_index[k] *= point
# sorted(lan_index)
# return languages[lan_index[0] / 5]
# solution(["SI JAVA JAVASCRIPT SQL PYTHON C#", "CONTENTS JAVASCRIPT JAVA PYTHON SQL C++", "HARDWARE C C++ PYTHON JAVA JAVASCRIPT", "PORTAL JAVA JAVASCRIPT PYTHON KOTLIN PHP", "GAME C++ C# JAVASCRIPT C JAVA"],
# ["PYTHON", "C++", "SQL"],
# [7, 5, 5])
def solution(table, languages, preference):
result = []
job = ['SI','CONTENTS','HARDWARE','PORTAL','GAME']
for i in table:
tmp=[]
for j in i.split(' '):
tmp.append(j) # 각 직군별 언어 순위를 tmp에 append
tmp.reverse() # 점수가 낮은 언어 순서대로 게산하기 위해 배열을 뒤집음
score = 0
for k in languages:
for l in tmp:
# 점수가 낮은 언어부터 language 배열의 몇번째 index에 있는지 구해서
# preference 배열에서 선호도 값 찾기
# 찾은 선호도 값과 해당 언어의 언어 점수에 +1을 해준 값을 곱해 score에 누적(배열의 index가 0부터 시작하므로 +1을 해줌)
if k==l:
score += preference[languages.index(k)] * (tmp.index(l) + 1)
result.append(score)
# result와 job을 튜플로 묶음
answer=list(zip(result,job))
# answer 배열을 score의 역순으로 정렬, 같은 score에 대해서는 job의 사전순으로 정렬
answer= sorted(answer, key = lambda x : (-x[0],x))
# 가장 높은 점수를 받은 과목명 출력
return answer[0][1]
solution(["SI JAVA JAVASCRIPT SQL PYTHON C#", "CONTENTS JAVASCRIPT JAVA PYTHON SQL C++", "HARDWARE C C++ PYTHON JAVA JAVASCRIPT", "PORTAL JAVA JAVASCRIPT PYTHON KOTLIN PHP", "GAME C++ C# JAVASCRIPT C JAVA"],
["PYTHON", "C++", "SQL"],
[7, 5, 5])